
The rapid progress in open source models, especially language models, has given rise to the belief that these models could pose a significant challenge to incumbent companies such as Google, Facebook and Microsoft.
While the idea of open source models dismantling the power of tech giants is appealing to many, it is important to remain realistic and recognize the major barriers the open source community still faces when trying to contend with proprietary models.
Open source AI: The successful underdog
In recent months, the open source AI community has witnessed significant advancements, starting with Meta’s LLaMA — the first impressive open source LLM that was leaked online. This sparked an influx of innovative research and creative development to rival ChatGPT, such as Falcon, Alpacaand Vicuna.
As seen below, these open source models are catching up with Vicuna almost surpassing Google Bard. Even though it uses fewer parameters than ChatGPT (13B compared to 175B), Vicuna was introduced as an “open source chatbot with 90% ChatGPT quality” and scored well in the tests performed.

One highlight was the community’s solution to a scalability problem with the new fine-tuning technique, LoRA, which can perform fine-tuning at a fraction of their normal costs.
In addition, consulting firm Semianalysis leaked a document by a Google engineer that even considered the open source community a real competitor, arguing that “we have no moat” and that they couldn’t withstand the power of open source labor across the globe.
The strongest case for open source models is the potential of disrupting smaller niche specific domains, where powerful AI may not be needed, and training smaller and cheaper open source models might be good enough. In addition, open source models are easier to customize, provide more transparency into training data, and give users better control over costs, outputs, privacy, and security.
However, beneath the surface, there are several drawbacks to open source AI, revealing that it is far from being a threat to incumbents.
Incumbents have more resources and capital.
During an event in Delhi, Sam Altman, the CEO of OpenAI, was questioned if it would be possible for three Indian engineers with a budget of $10 million to develop a project akin to OpenAI. Altman responded by asserting that it would be practically “hopeless” for such a young team with limited resources from India to create an AI model comparable to OpenAI. He further commented, “We’re going to tell you, it’s absolutely hopeless to compete with us on building foundation models, and you shouldn’t attempt it.”
Now you might be thinking, “well, he has to say that”, but the rationale behind his answer makes total sense. The way OpenAI’s chief scientist Ilya Sutskever explains it in short, is that “the more GPU, the better the models”. Or in other words, the more capital and resources, the better models can get. Ilya believes that academic research has and always will lag behind the powerful incumbents due to a lack of capital and engineering resources.
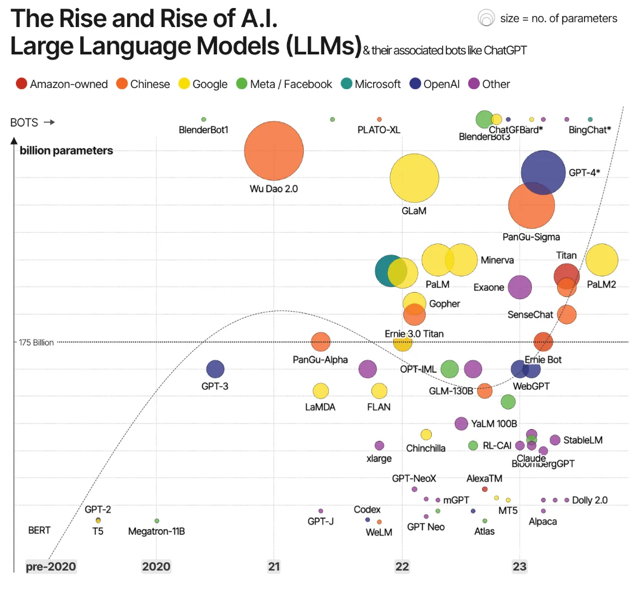
Since 2021, incumbents have quickly entered the race, offering both closed and open models that currently outperform the smaller ones, as seen below.
The flaws and drawbacks of mimicking LLMs
A critical issue with open source models lies in the algorithms used when trying to compete with proprietary models. A new study from UC Berkeleyhas identified that even though open source AI models have adopted clever techniques, such as fine-tuning their output or better models’ output, there remains a significant “capabilities gap” between open and closed models. Models fine-tuned this way adopt the style of the model they imitate but don’t improve in factuality. As a result, the open source community still faces the daunting challenge of pre-training state-of-the-art models — a task unlikely to be accomplished anytime soon.
Another inherent obstacle for open source AI is the hardware limitation of on-device inference. While the idea of running small and inexpensive customized LMs on local devices (such as computers or smartphones) is appealing, the current hardware limitations render it impossible to match the performance of proprietary server-hosted models like those offered by Google or OpenAI.
Technical challenges like the memory wall and data reuse problems, unresolved hardware trade-offs, and lack of parallelization across queries mean that open source AI models have an upper limit on their achievable efficacy.
Incumbents actually do have a moat
The business strategies executed by incumbent companies provide these firms with undeniable advantages that open source models cannot contend with. Contrary to popular belief, incumbents have powerful moats that protect their position. Not only do they have the financial resources, talent, brand, proprietary data, and power, but they also control the distribution of products that billions of people use daily. Leading tech companies are leveraging these advantages by enhancing their products and making AI an integral part of their offerings.
For example, Google has recently released new AI capabilities to their Search, Gmail, and Docs. Microsoft not only released similar capabilities to Office and Bing, but also partnered with OpenAI to offer a complete suite of cloud services on Azure to help businesses leverage AI at scale. Nonetheless, Microsoft owns GitHub and VStudio, two leading services for software engineers worldwide, and has already made a remarkable leap with Copilot. Amazon was next to follow with new services to AWS, such as Amazon Bedrock and Codewhisperer. If that’s not enough, Nvidia has recently launched DGX Cloud, an AI supercomputing service that gives enterprises immediate access to the infrastructure and software needed to train advanced models for generative AI and other groundbreaking applications.
This is just the tip of the iceberg, with many more examples from market leaders such as Adobe Firefly, Salesforce, IBM, and more.
The theory of the innovator’s dilemma might suggest that under the right circumstances, open source models have a chance to overthrow incumbent companies. The reality is far from this idealized scenario. Generative AI perfectly fits into the product suites and ecosystems that leading technology companies have already established.
On the contrary, start-ups and open source models have a great opportunity in disrupting domain-specific verticals, such as finance, legal, or other professional services, where incumbents are unlikely to compete or focus their efforts, and where open source models may prove to be an advantage, as they can be more customized and optimized for such verticals.
The Uphill Battle Open Source AI Models Continue to Face
In summary, while the progress made in the realm of open source models is indeed impressive, they still face many challenges that prevent them from competing with proprietary models in the long term. It is also fair to assume that proprietary models will only improve over time, becoming much cheaper, faster, customizable, safer, and more powerful.
From algorithmic to hardware restraints and the entrenched advantage of incumbents, open source models face an uphill battle in achieving the level of success and acceptance necessary to unsettle established giants. As AI becomes increasingly commoditized with the products and services offered by incumbent companies, the likelihood of open source models effectively upending the current dynamics diminishes further.
The future of open source models shows great potential, but it is important to maintain a grounded perspective and recognize the immense obstacles that stand in its way.